介绍
pandas-profiling可以为DataFrame生成一份报告,在pandas中 df.describe() 是比较基础的探索性数据分析函数,而pandas_profiling则是在DataFrame的基础上扩展,用于快速数据分析。
对于每个column,以下统计信息(与列类型相关)将显示在交互式HTML报告中:
- 类型推断:检测DataFrame中列的类型。
- 概要:类型,唯一值,缺失值
- 分位数统计信息,例如最小值,Q1,中位数,Q3,最大值,范围,四分位数范围
- 描述性统计数据,例如均值,众数,标准偏差,和,中位数绝对偏差,变异系数,峰度,偏度
- 出现频率高的值
- 直方图
- 高度相关变量(Spearman,Pearson和Kendall矩阵)的相关性分析
- 缺失值:矩阵,计数(count),热图和缺失值树状图
- 重复行列出出现次数最多的重复行
- 文本分析:了解文本数据的类别(大写,空格),脚本(拉丁,西里尔字母)和块(ASCII)
安装
使用pip安装
pip install pandas-profiling
使用conda安装
conda install -c anaconda pandas-profiling
一行代码生成报告
首先导入测试数据,这里我们使用tushare获取的股票数据来进行测试。
import pandas as pd
import tushare as ts
from pandas_profiling import ProfileReport
pro = ts.pro_api()
symbol = '000001.SZ'
df = ts.pro_bar(ts_code=symbol, adj='qfq', start_date='20200101', end_date='20201113')
df.index = pd.to_datetime(df['trade_date'])
df.index.name = None # 这步不可缺少,否则生成报告时同名列会报错
df.sort_index(inplace=True)
接下来生成测试报告
report = ProfileReport(df.sample(frac=0.05), title='%s 股票分析' % symbol)
report.to_file(output_file='%s.html' % symbol)
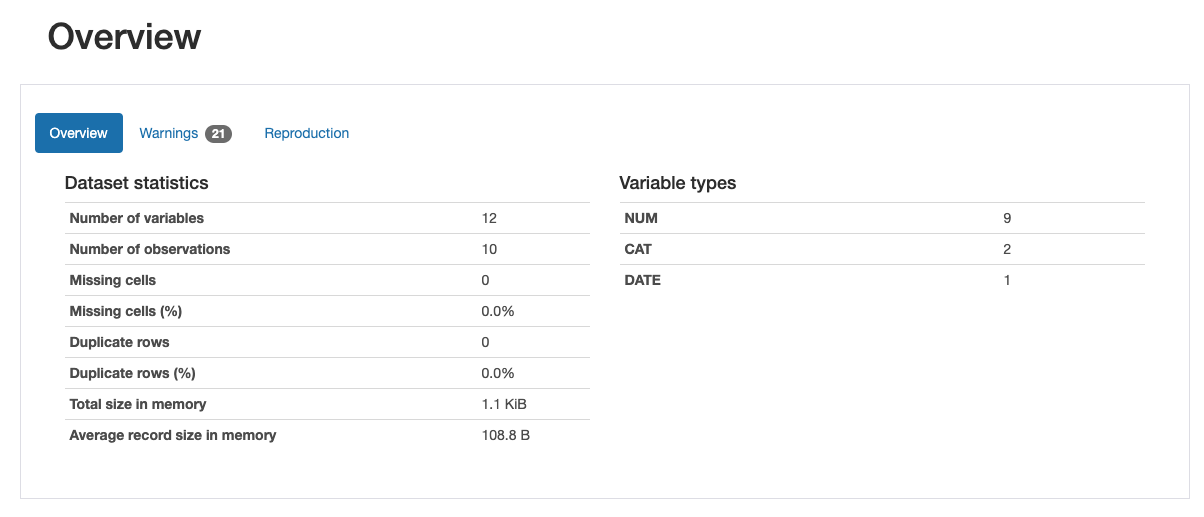
报告汇总信息如下截图
大数据问题解决方案
当pandas-profiling应用在大数据量的DataFrame上运行速度会非常慢,这时候可以考虑使用以下办法解决。
1. Minimal模式
在此模式下report会去掉一些耗时的计算操作,生成一份简略的数据分析报告。通过将参数minimal设置为True可以开启此模式。
profile = ProfileReport(large_dataset, minimal=True)
profile.to_file("output.html")
2. 采样
采样方式可以有效降低数据量,但缺点是可能漏掉某些数量较小的错误情况。
tmp = df.sample(100) # 方法1,随机采样100条数据
tmp = df.sample(frac=0.01) # 方法2,返回数据的比例,不可以跟上面的数值同时使用
参考
https://pandas-profiling.github.io/pandas-profiling/docs/master/rtd/


